
In this edition, I’ll deal with some Python codes and help you find the websites that you would visit more often. Assuming that you don’t clear your history often, I advise you to prepare yourself a little for any sizeable impact or perhaps, regret, upon seeing your browsing activities.
I am focusing on the more common audiences here. So, I’m going to jump straightaway into the layout of my little python (2.7) script that I used to analyze my Chrome’s history on Windows, which eventually led to a little epiphany moment.
Chrome’s history database
Chrome stores its data locally in an SQLite database. So all we need to do here is write a consistent Python code that would make a connection to the database, query the necessary fields and extract the required data, which is the URLs visited and the corresponding total visit counts, and churn it out like a puppy.
On a Windows machine, this database usually can be found under the following path.
C:\Users\<YOURUSERNAME>\AppData\Local\Google\Chrome\User Data\Default
As my code is focused on Chrome on Windows, I will leave the code for yourself to tweak it for Linux and Mac. The following code gives us the path on Windows.
data_path = os.path.expanduser('~')+"\AppData\Local\Google\Chrome\User Data\Default"
files = os.listdir(data_path)
history_db = os.path.join(data_path, 'history')Now that we have the path and the database name, we shall do some SQL operations in it. To do that, you’d need to import the sqlite3 library that comes with Python. The variables are self-explanatory. If necessary, refer the sqlite3 documentation.
c = sqlite3.connect(history_db) cursor = c.cursor() select_statement = "SELECT urls.url, urls.visit_count FROM urls, visits WHERE urls.id = visits.url;" cursor.execute(select_statement) results = cursor.fetchall()
The important thing here is the select_statement. How did I know which fields to fetch from the table? Well, you could either download the SQLite browser and get a glimpse of the schema or get the table and run a master fetch of the table from the console.
So, when the program runs, the fetchall function returns a list of tuples. Go ahead and try printing it. You’d end up with a console full of tuples with the website and the number of times the URL was visited in a particular session or interval, as values. Though it helps us to get a gist of our history, it’s not helpful in this format. The URL is repetitive and I have no idea why the visit count are scattered along the list. However, we can loop every occurrence of the URL, make our own count, and associate these two as a key-value pair in a dictionary.
Parsing URLs
If you print the tuple in the console, we can understand that the counts are much lesser than expected. This is due to the different counts for both HTTP, HTTPS URLs, including the subdomains. While the following parsing part is not the pythonic way to do it, I decided to go with a nifty function that would split the URL into components and return the plain naked domain. For consistency, I’d recommend you to use the urlparse library and use the netloc function to do it in a better way.
def parse(url):
try:
parsed_url_components = url.split('//')
sublevel_split = parsed_url_components[1].split('/', 1)
domain = sublevel_split[0].replace("www.", "")
return domain
except IndexError:
print "URL format error!"Creating and sorting the URL, Count dictionary
As seen above, now all we have to do is to loop through the list of tuples, fetch the URL, parse it and then add it to a dictionary as a key, and for every occurrence for the URL, you simply add an incremental counter forwarded as the value.
sites_count = {} #dict makes iterations easier :D
for url, count in results:
url = parse(url)
if url in sites_count:
sites_count[url] += 1
else:
sites_count[url] = 1
As Python’s dictionary is intrinsically not ordered, it should be sorted by the value for a clean result. I’ve used the OrderedDict method to do that.
sites_count_sorted = OrderedDict(sorted(sites_count.items(), key=operator.itemgetter(1), reverse=True))
Analyzing and plotting the results
Now that we have all we need in a good shape, all you need to do is to put up a strong face and pile up all the energy in you to feel whatever it is that you would feel when finding your most visited sites. I hardly have any experience in plotting with matplotlib, so the following is the simplest graph I could come up with.
plt.bar(range(len(sites_count_sorted)), sites_count_sorted.values(), align='edge') plt.xticks(rotation=45) plt.xticks(range(len(sites_count_sorted)), sites_count_sorted.keys()) plt.show()
While you might choose to plot only the first fifty or hundred sites, I chose to plot every damn URL I visited. This is my graph as on April 20, 2016, showing a zoomed-in snapshot of the primary sites I spend my time on.
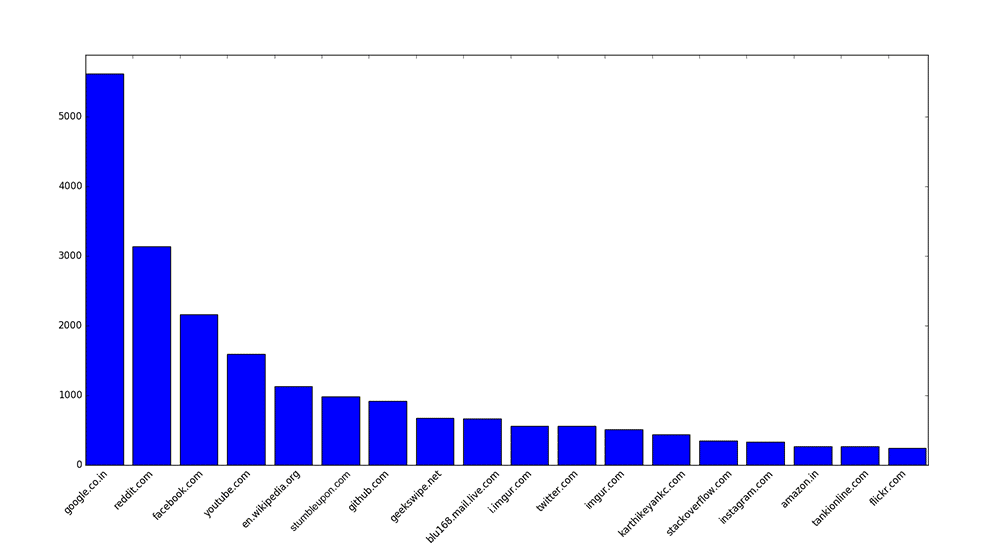
Time well spent!
Complete code – Python history analyzer for Chrome
Feel free to fork it and tweak it.
import os
import sqlite3
import operator
from collections import OrderedDict
import matplotlib.pyplot as plt
def parse(url):
try:
parsed_url_components = url.split('//')
sublevel_split = parsed_url_components[1].split('/', 1)
domain = sublevel_split[0].replace("www.", "")
return domain
except IndexError:
print "URL format error!"
def analyze(results):
prompt = raw_input("[.] Type <c> to print or <p> to plot\n[>] ")
if prompt == "c":
for site, count in sites_count_sorted.items():
print site, count
elif prompt == "p":
plt.bar(range(len(results)), results.values(), align='edge')
plt.xticks(rotation=45)
plt.xticks(range(len(results)), results.keys())
plt.show()
else:
print "[.] Uh?"
quit()
#path to user's history database (Chrome)
data_path = os.path.expanduser('~')+"\AppData\Local\Google\Chrome\User Data\Default"
files = os.listdir(data_path)
history_db = os.path.join(data_path, 'history')
#querying the db
c = sqlite3.connect(history_db)
cursor = c.cursor()
select_statement = "SELECT urls.url, urls.visit_count FROM urls, visits WHERE urls.id = visits.url;"
cursor.execute(select_statement)
results = cursor.fetchall() #tuple
sites_count = {} #dict makes iterations easier :D
for url, count in results:
url = parse(url)
if url in sites_count:
sites_count[url] += 1
else:
sites_count[url] = 1
sites_count_sorted = OrderedDict(sorted(sites_count.items(), key=operator.itemgetter(1), reverse=True))
analyze (sites_count_sorted)If you have any issues, please do let me know in the comments or at GitHub. Have fun.



i got an error like this. please say what is the eroor and how to clear it.
files = os.listdir(data_path)
FileNotFoundError: [WinError 3] The system cannot find the path specified: ‘C:\\Users\\Gayathri\\AppData\\Local\\Google\\Chrome\\User Data\\Default’
Is there any way I can make this work in Jupyter notebook?
Hello. The code is working but getting an error database locked..how can i Solve this. Thanks alot
You need to close the browser before you run the script.
(Unicode error) 'unicodeescape' codec can't decode bytes in position 28-29: truncated \UXXXXXXXX escapedata_path=os.path.expanduser('~')+"\AppData\Local\Google\Chrome\User Data\Default" taking "(Unicode error) ‘unicodeescape’ codec can’t decode bytes in position 28-29: truncated \UXXXXXXXX escape"Error!!! how can it be solved ?I have modified Data_path like
data_path=os.path.expanduser('~')+ r"\AppData\Local\Google\Chrome\User Data\Default" and applied "r+"\AppData\Local\Google\Chrome\User Data\DefaultNow gettingsqlite3.OperationalError: database is lockedHow to unlock the database? Pls explain.
The database will be locked when the browser is running in the background. You need to close your browser before you run the script.
now closed and running fine
If your ‘\’ is not escaped properly, this might happen. In the following response, I see that you have converted the path into raw string. That should work.
Now I am getting the error
for url, credentials in credential.iteritems():" below AttributeError: 'dict' object has no attribute 'iteritems'.How can this be resolved?
Please read the article again. Use Python 2.7.x instead of Python 3. Or, if you are using Python 3, use
credential.items().Getting below error
f.write("\n"+url+"\n"+credentials[0].encode('utf-8')+ " | "+credentials[1]+"\n")TypeError: must be str, not bytes
where we using string? y mentioned not bytes?
i modified
credential.items()infor url, credentials in credential.items():statementPlease use Python 2.7.x. Or make appropriate changes to the code if you want to use Python 3. Refer this – https://docs.python.org/3.0/whatsnew/3.0.html#text-vs-data-instead-of-unicode-vs-8-bit
i am using python 3.6… if it is good or not?
Python 3.6 is good. But the code above is written in Python 2.7. So if you want the code to run, use Python 2.7. I can’t really make this clear any more. :)
Karthikeyan KC, how to view Browsing Internet Explorer History with Python?
I need “data_path” and “select_statement ” like Chrome.
This script is for Chrome only. For browsers like Firefox it’s only a matter of modifying the SQL query. I can’t help you with internet explorer.
Hey! nice article , i wanted to know how can i scrape the browsing history for a remote computer or any device and what information do i need and is that possible with python.
What are you actually trying to accomplish by this? The above code is to get one’s own browser history and it is supposed to be a fun script for learning and analysis purposes. You are asking to remotely access a browser and record its history. I can’t help you here.
how to get chrome search history using vb.net. give ans
Please stop spamming the comment section. You need not ask me more than once. The above script is written in Python. The logic is self explanatory. Go figure out a way to write one in VB .net. Also, note that I’ll have to place a ban on you if you keep spamming the comments.
I love this! Now can you turn it into something button pushing simple for a Python beginner so I could just run it and see my outputs? Just kidding….. I was looking for something I can use to help me determine some client time for billing and ran across you …… I know this isn’t it, but I still loved it when I ran across it…… you are great! thanks for sharing!! I’ve got to come back to this when I know more about how to work in Python on my machine…. I’m a programmer from the days of Cobol and C (before the +) and I’m self learning web development and doing ok ….. it’s just hard to know where to start sometimes …. some days I think I need to go back to school and start over, but who would pay my bills? lol
You write some of the best python tutorials online for specific tasks and include easy to understand introductions. Thank You. I hope in the future you will also keep in mind those using Python 3x, some things like the windows path, and input() have changed and the above code wont work unless the user knows about those changes.
Thank you Spunk! I will keep that in mind for my upcoming articles. :)
Hi
Great tutorial – i was able to extract the history no worries.
I cannot plot the graph though.
I’m wondering if it is because of:
1 – your analysis code looks different to the analyze method in the complete code – is there a reason for this?
2 – perhaps i have not fed (put) the right parameter/arg into my copy of your analze method?
I am realtively new – so any help would be greatly appreciated
regards,
m :)
Hello! :) This is the part that plots the graph.
Would help if you could give me any info about the errors.
Hye, I tried following you ! But once I make a connection object aka cursor and try printing my results using fetchall function I am getting an error saying DB is locked. What should I do Now? I am stucked here..
You need to close the browser before you run the script.
I did that too..!!!
You could try copying the database to a new location and then try accessing it from there.
is there a way to get the search keyword, page title and URL altogether? By using one SQL statement?
You can use
UNION ALLto do that!Hi,
I just tried your code and get the following error:
sqlite3.OperationalError: no such table: urls
Has the name of the table changed?
No, the table names haven’t changed as of V 55.0.2883.87. You can list all the tables by using the following snippet.
The urls table exists.
